
Data scientists may simply design and deploy machine learning applications using Azure ML, a cloud-based machine learning platform. The text categorization template, which is based on the occurrence frequencies of words and n-grams, can be customized to fit various text categorization circumstances.
Azure Machine Learning (Azure ML) is a cloud-based service that permits operators to generate and achieve machine learning solutions.
It’s intended to assist data scientists and machine learning consulting in optimizing the use of their existing data processing and model creation skills and frameworks. It also aids in the scaling, distribution, and deployment of cloud workloads.
In this blog, we are going to demonstrate how we are going to train our model using NLTK (Natural Language Toolkit ) which is developed with the help of Python to do text classification and generate an auto response on support tickets through Azure services and create a model which is later deployed on Azure service. The model trained on 80 % trained data and rest by testing data.
Save Time and Efforts
This will Empower developers and data scientists with a wide range of productive experiences for building, training, and deploying machine learning models faster.
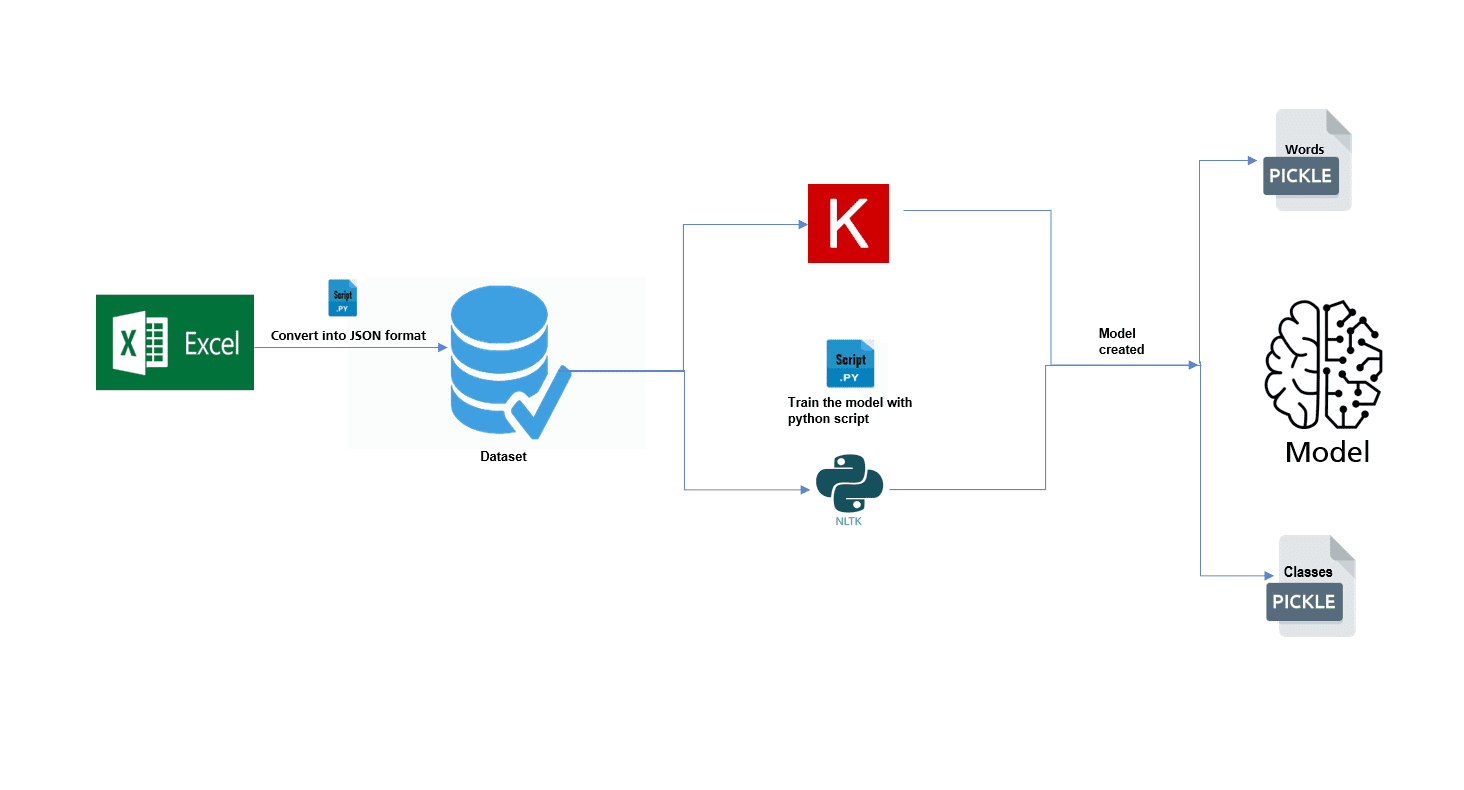
The process to achieve this
- Create a dataset in JSON Intents format
- Load the dataset and perform preprocessing and data cleansing on the dataset
- Use Python NLTK tool for the work tokenization
- Extract features
- Build a model
- Test the accuracy
Lesson details
- Create Dataset:
For the dataset, we have to change the emails into CSV files or in any other extract format so that we can classify it easily. Then we have to set different labels as per the requirements on the emails so that we can analyze them.
- Load Dataset :
For email classification, we have to load the dataset with the help of this library Pandas. With the help of libraries, we can manipulate and classify the data. Before training of models we have to perform certain tasks on the dataset e.g. data cleansing and then data preprocessing for accurate predictions.
- Split into training and test data :
With the help of algorithms, we can identify the classification. With the help of CountVectorizer, we can count how many words we will get.
- Extract Features :
In the feature extraction process, we aim to reduce the number of features in the datasets by creating new features from the existing ones. These newly created sets of features able to categorize most of the information contained in the original set of features.
- Build a model :
In the machine learning lifecycle, the model refers to a mathematical expression of the model parameters along with input placeholders for each prediction, class, and action for regression, classification, and reinforcement categories respectively. This expression is embedded in the single neuron as a model.
- Test the Accuracy
Then we test the accuracy after training the model 80% and create the test cases.
Implementation in Azure machine learning services:
- Create ML experiment
- Set up workspace & dev environment
- Train your model with python script.
- Batch score models with pipelines
- Prepare your code for production
What is Text-Classification?
Text classification is the process of assigning labels to the text. Text classification is the task of assigning a set of predefined categories to free-text. A fairly popular text classification task is to identify a body of text as which category or class text belongs to, for things like email filters.
Conclusion
Azure ML makes it much easier to create predictive, descriptive, and prescriptive analyses. Azure Machine Learning provides a basic infrastructure on which we may build machine learning models based on existing knowledge in the quality demanded by businesses.







