
This is the first blog in a hopefully a long series of blogs where I will publish for utilizing the full potential of the hardware resources for developing the AI solutions.
As an AI/ML developers! In today’s world, the models we build are only as powerful as the hardware that runs them. Complex architectures like Transformers and diffusion models have created an enormous demand for computational power, elevating one piece of hardware to supreme importance: the Graphics Processing Unit (GPU).
However, a powerful GPU alone isn’t enough. To maximize its potential, you must understand the complete ecosystem—everything from proper system configuration and essential software layers like CUDA to writing code that effectively leverages the GPU’s parallel processing capabilities.
Why GPUs Dominate AI?
At its core, deep learning is a series of massive parallel computations, primarily matrix multiplications and tensor operations. While a CPU is a master of sequential tasks with a few powerful cores, a GPU is a specialist in parallel workloads, featuring thousands of smaller, efficient cores. This architectural difference is the key to their dominance in AI.
- CPUs: Designed for low latency on sequential tasks.
- GPUs: Designed for high throughput on parallel tasks.
This massive parallelism enables GPUs to execute the billions of floating-point calculations required for neural network training at unprecedented speeds. Modern NVIDIA GPUs can perform matrix multiplications up to 100-200 times faster than high-end CPUs, reducing training times from weeks to hours or even minutes. Beyond raw computational power, NVIDIA has created a comprehensive software ecosystem including CUDA (their parallel computing platform), cuDNN (deep neural network library), TensorRT (inference optimizer), and NCCL (multi-GPU communication library). This integrated hardware-software approach has established NVIDIA as the dominant force in AI development, with over 90% market share in training hardware and widespread framework support across PyTorch, TensorFlow, JAX, and other popular AI frameworks.

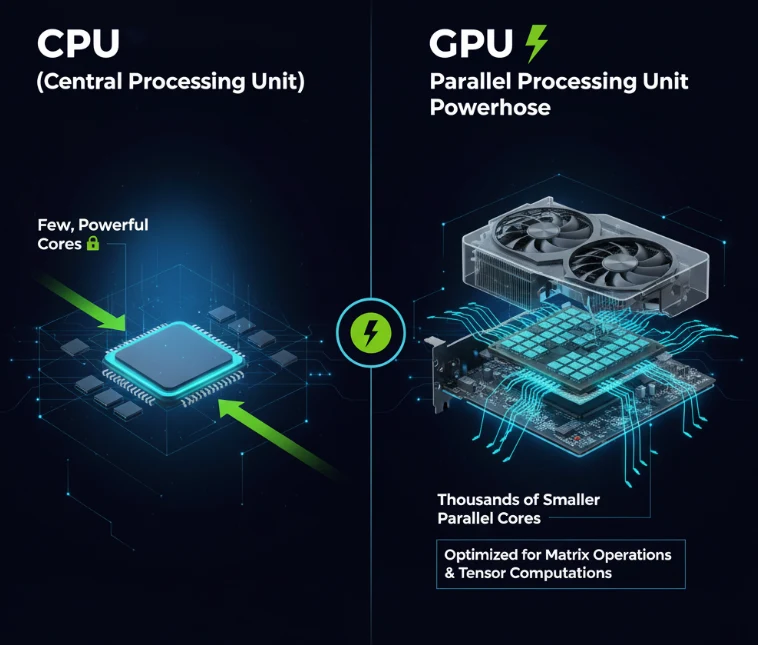
An infographic comparing a CPU’s few, powerful cores to a GPU’s thousands of smaller cores.
Building Your AI Powerhouse: System Setup
Before you can write a single line of code, you need a system that’s ready for the task.
Hardware Considerations:

Hardware Stack and Support.
- GPU: The most critical component.
- Consumer Grade (e.g., GeForce RTX series)
- Professional/Data Center Grade (e.g., NVIDIA A100, H100)
- CPU: A powerful CPU is still vital to prevent data bottlenecks.
- RAM: You'll need enough system RAM to handle your datasets.
- Storage: A fast NVMe SSD is essential for quick data loading and checkpointing.
Software Stack Installation:
1. Operating System: Ubuntu Linux is the gold standard for AI development due to its stability and superior driver support. Windows users can leverage the Windows Subsystem for Linux (WSL2) for a native Linux environment with GPU passthrough.
2. NVIDIA Drivers: Install the latest stable drivers for your specific GPU from the NVIDIA website.
3. CUDA Toolkit: This is NVIDIA’s parallel computing platform and API. It’s the fundamental layer that allows software to access the GPU for general-purpose computing. You can verify the installation by running the nvidia-smi command in your terminal.
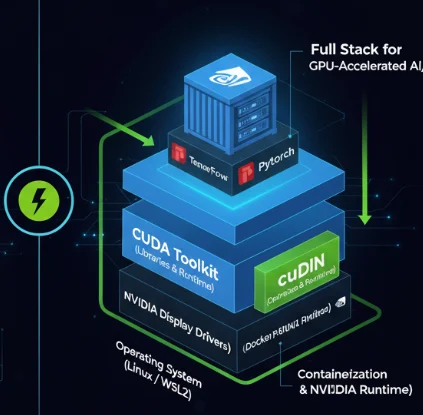
Software Stack and support
4. cuDNN (CUDA Deep Neural Network library): This is a GPU-accelerated library of primitives for deep neural networks. Frameworks like TensorFlow and PyTorch will automatically use cuDNN when it’s detected, providing a significant performance boost.
5. Containerization (Docker): To avoid dependency hell, it’s highly recommended to use Docker with the NVIDIA Container Toolkit. You can pull official, pre-configured images from the NGC (NVIDIA GPU Cloud) catalog that already have the drivers, CUDA, and cuDNN set up correctly.
The Bridge to Performance: CUDA and cuDNN
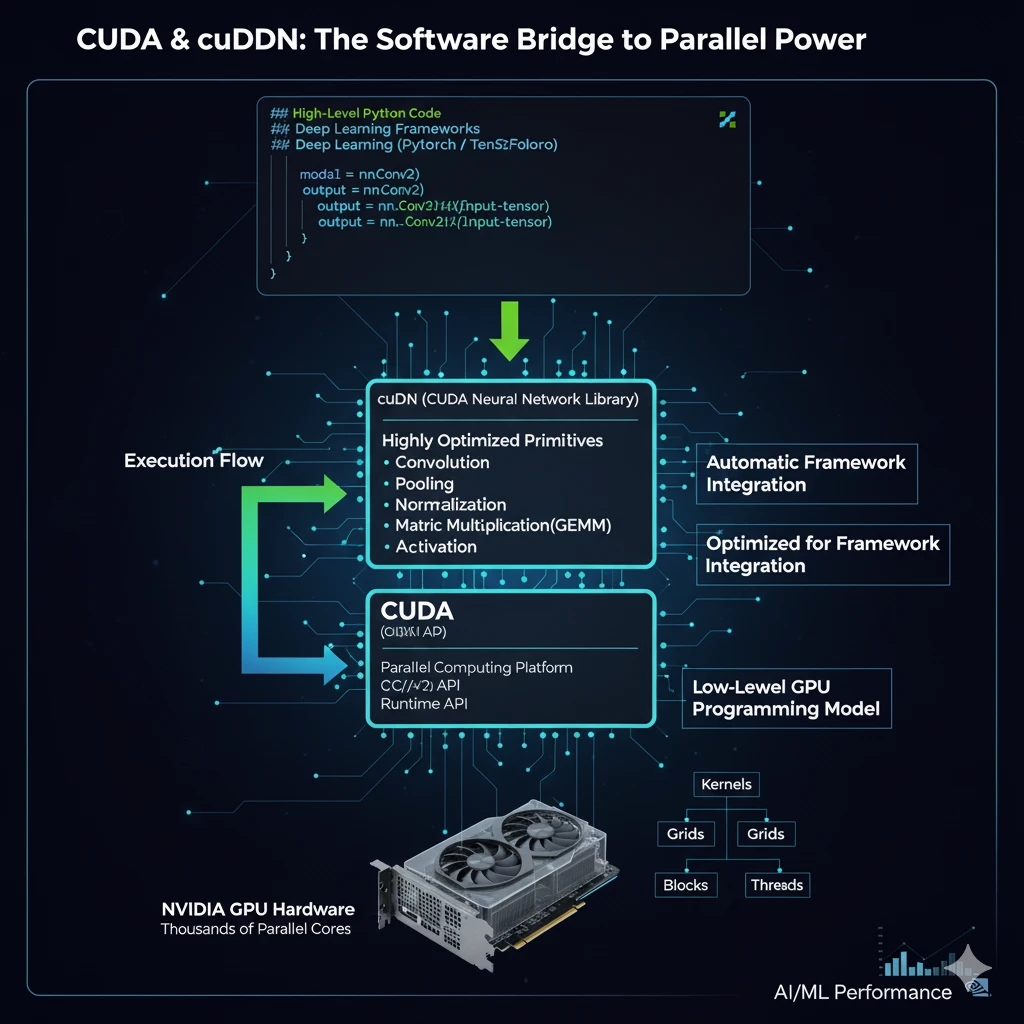
- CUDA (Compute Unified Device Architecture): Think of CUDA as the low-level language that lets your application "speak" directly to the GPU's parallel processing capabilities. It extends languages like C/C++ and provides APIs for others, allowing developers to write "kernels" - functions that are executed in parallel across the GPU's many cores.
- cuDNN: While you could, in theory, write your own CUDA kernels for neural network operations, you'd be reinventing the wheel. cuDNN provides a library of pre-written, highly optimized kernels for the most common deep learning operations. NVIDIA's engineers have spent countless hours tuning these primitives for maximum performance on their hardware, so you don't have to.
When your PyTorch or TensorFlow code calls for a convolution, it’s actually cuDNN that’s executing that operation on the GPU with maximum efficiency.
Conclusion: The Foundation is Set
We’ve now covered the essential groundwork for GPU-powered AI. You understand why GPUs are critical, how to build and configure a capable system, the role of the NVIDIA software stack, and the fundamental coding practices to ensure your GPU is actively engaged.
But this is just the beginning. With our machine ready and our theoretical knowledge in place, it’s time to apply this power to the diverse and exciting models that define modern AI.
Stay tuned for our next post, where we’ll dive into the code and explore how GPUs accelerate everything from Large Language Models and object trackers to advanced AI agents.